
Современная ИТ-инфраструктура всё чаще строится вокруг контейнеризированных приложений, и управление системами на k8s становится ключевой компетенцией для инженеров и администраторов. Kubernetes, или сокращённо k8s, превратился из экспериментальной технологии в стандарт оркестрации контейнеров, позволяющий автоматизировать развертывание, масштабирование и управление приложениями в продакшен-среде . Компания, внедряющая эту платформу, принципиально меняет подход к эксплуатации: вместо управления отдельными виртуальными машинами и написания скриптов деплоя инженеры описывают желаемое состояние системы декларативно. Как показывает практика перехода на контейнерную оркестрацию в крупных проектах, Kubernetes обеспечивает масштабируемость и гибкость, но требует пересмотра привычных процессов и внедрения новых инструментов.
Архитектура Kubernetes: из каких компонентов состоит система управления
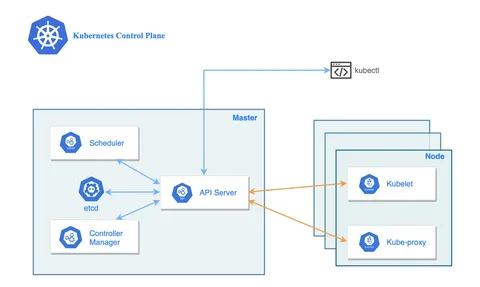
Эффективное управление системами на k8s невозможно без понимания его архитектуры. Кластер Kubernetes состоит из двух основных частей: control plane (плоскость управления) и worker nodes (рабочие узлы) . Control plane принимает глобальные решения о состоянии кластера и обрабатывает события. Центральным компонентом здесь является etcd — распределённое высоконадёжное хранилище ключей-значений, где хранится вся конфигурация и состояние кластера . Потеря или повреждение данных etcd может привести к длительным простоям, поэтому резервное копирование и контроль версий — обязательная практика в промышленной эксплуатации .
Остальные компоненты control plane включают kube-apiserver — единственную точку входа для всех управляющих команд, scheduler (планировщик), который распределяет поды по узлам с учётом доступных ресурсов и ограничений, и контроллеры, следящие за тем, чтобы реальное состояние кластера соответствовало желаемому . На каждом worker node работает kubelet — агент, который управляет жизненным циклом контейнеров и докладывает состояние узла в apiserver . Без kubelet управление контейнерами стало бы нестабильным и непредсказуемым, так как именно он обеспечивает регулярную проверку состояния и восстановление контейнеров .
Ключевые объекты Kubernetes: Pod, Deployment, Service и другие
Для практического управления системами на k8s необходимо освоить основные объекты API. Pod — это минимальная и неделимая единица в Kubernetes, представляющая собой группу из одного или нескольких контейнеров, которые разделяют сеть и хранилище . Именно поды, а не отдельные контейнеры, планируются на узлы. Deployment — декларативный способ управления подами, который обеспечивает обновления и откаты приложений, управление ReplicaSet (набором реплик подов) и автоматическое восстановление при сбоях .
Service — это абстракция, которая определяет сетевой доступ к группе подов и обеспечивает балансировку нагрузки . Без Service поды были бы временными и недоступными извне. Ingress — это HTTP-балансировщик, который маршрутизирует внешний трафик к сервисам внутри кластера по правилам (например, по доменным именам или путям URL) . Для управления состоянием приложений, хранящих данные, используются StatefulSet — он гарантирует уникальность и стабильность имён подов, порядок их запуска и сохранение состояния при перезапусках .
- ReplicaSet — контроллер, поддерживающий заданное количество идентичных подов .
- DaemonSet — обеспечивает запуск пода на всех или выбранных узлах кластера (например, для сбора логов или мониторинга) .
- Job и CronJob — для выполнения одноразовых или периодических задач (бэкапы, миграции данных) .
- ConfigMap и Secret — для хранения конфигураций и чувствительной информации (паролей, токенов) отдельно от образов контейнеров .
«Kubernetes давно перестал быть экспериментом и превратился в стандарт для запуска распределённых приложений. Это платформа, которая позволяет собрать вместе контейнеры, сеть, хранилище и политику в единую систему управления» .
Управление хранилищами и данными в кластере
Работа с данными — один из самых сложных аспектов управления системами на k8s. В Kubernetes принято разделение хранилищ на два основных типа: постоянные и временные . Временные хранилища (emptyDir) связаны с жизненным циклом пода и используются для данных, актуальных только во время работы контейнера . Постоянные хранилища (PersistentVolume, PV) представляют собой сегменты дискового пространства, которые могут быть подключены к подам и сохранять данные даже после перезапуска или удаления контейнера .
Для запроса хранилища приложения используют PersistentVolumeClaim (PVC) — это механизм, позволяющий абстрагироваться от физической реализации хранилища . В рамках управления системами на k8s важно понимать разницу между статическим и динамическим предоставлением хранилищ. При статическом подходе администратор заранее создаёт PV. При динамическом — используется StorageClass, который автоматически создаёт PV при появлении PVC . Для приложений с состоянием (базы данных, очереди) критически важно правильно настроить StatefulSet и соответствующие PVC, чтобы при масштабировании или обновлении данные не терялись .
- emptyDir — временное хранилище, очищается при удалении пода.
- hostPath — монтирование директории с узла, полезно для разработки, но небезопасно в production .
- PersistentVolume (PV) — ресурс хранилища в кластере, абстракция над физическим диском.
- PersistentVolumeClaim (PVC) — запрос на хранилище от приложения, привязан к неймспейсу .
Сравнение типов хранения данных в Kubernetes
| Тип хранилища | Жизненный цикл | Использование | Сохраняет данные при перезапуске пода | Примеры |
|---|---|---|---|---|
| emptyDir | Времени пода | Временные файлы, кэш | Нет | Кэш веб-сервера |
| hostPath | Узла | Разработка, доступ к файлам узла | Да (на одном узле) | Мониторинг логов узла |
| PersistentVolume (PVC) | Независим от пода | Постоянные данные (БД, файлы пользователей) | Да | PostgreSQL, MinIO |
| ConfigMap / Secret | Независим от пода | Конфигурации и секреты | Да (только данные) | Переменные окружения |
При работе с хранилищами важно контролировать запросы (requests) и лимиты (limits) ресурсов, чтобы избежать истощения дискового пространства на узлах. Без контроля ресурсов кластер быстро разрастается, и расходы уходят за пределы бюджета .
«В моём опыте операторы сильно сокращают ручную работу, но требуют внимательного тестирования и управления правами доступа. Custom Resource Definitions расширяют API кластера, позволяя описывать доменные объекты как родные ресурсы» .
Сети и балансировка нагрузки в Kubernetes
Сетевая инфраструктура Kubernetes — ещё одна фундаментальная область управления системами на k8s. В кластере существует несколько типов сетей: сеть узлов, сеть подов и сеть сервисов. Сетевые плагины, реализующие спецификацию CNI (Container Network Interface), такие как Flannel, Calico или Cilium, отвечают за связь между подами на разных узлах и реализуют модель сети . Ошибки на уровне сети часто маскируются как проблемы приложений, поэтому проверка CNI становится одной из первых диагностик при инцидентах .
Service обеспечивает стабильную точку входа для доступа к подам, IP-адреса которых могут меняться. Типы Service: ClusterIP (только внутри кластера), NodePort (открывает порт на каждом узле) и LoadBalancer (интеграция с облачным балансировщиком) . Для маршрутизации HTTP-трафика используется Ingress Controller (например, NGINX Ingress), который по правилам Ingress направляет запросы на разные внутренние сервисы. Понимание работы сетевых политик (Network Policies) критично для безопасности: они позволяют ограничивать трафик между подами и неймспейсами, реализуя принцип Zero Trust внутри кластера .
Инструменты для управления и автоматизации
Современное управление системами на k8s немыслимо без автоматизации и правильных инструментов. kubectl — основной CLI-инструмент для взаимодействия с API Kubernetes . Но для промышленной эксплуатации нужны более мощные решения. GitOps превращает Git-репозиторий в единственный источник правды о состоянии системы. Инструменты вроде ArgoCD или Flux автоматически синхронизируют состояние кластера с конфигурациями в репозитории: изменения проходят через Pull Request, проверяются CI и затем автоматически применяются в кластере .
Helm — менеджер пакетов для Kubernetes, который позволяет упаковать приложение в чарт (chart) и разворачивать его как единое целое . Kustomize — инструмент для управления конфигурациями без шаблонов, позволяющий «конфигурировать конфигурации» и накладывать патчи для разных окружений (dev, stage, prod) . CI/CD конвейеры (например, на Jenkins или GitLab CI) тесно интегрируются с Kubernetes для автоматизации сборки, тестирования и развертывания .
«Ключ к устойчивой эксплуатации — баланс между автоматизацией и контролем. Автоматизируйте повторяющиеся действия, но сохраняйте видимость и контроль над изменениями. Это позволит масштабировать платформу и при этом оставаться уверенным в её поведении при любых нагрузках» .
Мониторинг, масштабирование и безопасность
Мониторинг — обязательный компонент управления системами на k8s. Стандартный стек наблюдения в мире Kubernetes — Prometheus для сбора метрик и Grafana для визуализации . Prometheus собирает метрики с компонентов кластера (kubelet, etcd, apiserver) и с самих приложений (если они предоставляют эндпоинт в формате Prometheus). Для логирования используются Loki (легковесное решение, интегрируемое с Grafana) или стек ELK (Elasticsearch, Logstash, Kibana). Для распределённой трассировки (отслеживания запросов через микросервисы) применяется Jaeger или Zipkin .
Масштабирование в Kubernetes реализуется на нескольких уровнях. Horizontal Pod Autoscaler (HPA) автоматически увеличивает количество реплик подов на основе наблюдаемой метрики (обычно CPU или памяти) . Vertical Pod Autoscaler (VPA) корректирует requests и limits для подов на основе исторических данных о потреблении ресурсов . На уровне кластера работает Cluster Autoscaler, который добавляет или удаляет физические узлы (worker nodes) при нехватке или избытке ресурсов .
Безопасность в Kubernetes многогранна. RBAC (Role-Based Access Control) управляет правами пользователей и сервисных аккаунтов на уровне API . Важно следовать принципу наименьших привилегий. Network Policies ограничивают сетевой трафик. Pod Security Standards и OPA (Open Policy Agent) позволяют применять политики безопасности к подам (запрет на запуск от root, запрет на привилегированные контейнеры) . Также необходим контроль уязвимостей в контейнерных образах на этапе CI/CD.
«Управление системами на k8s — это не только набор утилит, но и культура работы: тесты, ревью конфигураций, документированные процедуры. Без этих элементов любая автоматизация рано или поздно приведёт к неуправляемому состоянию» .
Типичные ошибки и практические советы
Опытные инженеры выделяют несколько типичных ошибок при управлении системами на k8s. Первая ошибка — недооценка наблюдаемости: без покрытия логами, метриками и трассировкой сложные сбои остаются необъяснимыми, а инциденты затягиваются на часы . Вторая — попытка изменить всё единовременно: слишком крупные релизы, смешивание множества изменений и отсутствие контрольных точек приводят к длительным откатам и простою сервисов. Третья — игнорирование стоимости: без контроля ресурсов (requests/limits) и мониторинга затрат кластер быстро разрастается, и расходы на облачные ресурсы становятся неуправляемыми .
Стратегии обновлений (Rolling Update, Blue/Green, Canary) помогают минимизировать риски. Rolling update — обновление подов постепенно, с заданным maxSurge и maxUnavailable. Blue/Green — одновременное существование двух окружений (синее — текущее, зелёное — новая версия) с быстрым переключением трафика. Canary — постепенное направление небольшого процента трафика на новую версию для проверки . Важную роль играют readinessProbe и livenessProbe — проверки готовности и живости пода, которые определяют, когда под может принимать трафик и нужно ли его перезапустить .
«Когда я начинал работу с Kubernetes, одна из первых задач была причесать хаотичные манифесты и выстроить GitOps-процесс. Переход занял время, но дал результат: быстрее развертывались исправления, исчезли «ручные» правки в кластере, и откат стал предсказуемым» .
Зрелое управление: GitOps и культура
Переход к зрелому управлению системами на k8s означает внедрение GitOps-культуры. В этом подходе вся конфигурация Kubernetes (деплойменты, сервисы, конфигмапы) хранится в Git. ArgoCD отслеживает изменения в репозитории и автоматически применяет их в кластере . Это даёт полную историю изменений, упрощает аудит и откаты, а также решает проблему дрифта (расхождения) конфигураций между окружениями.
Инвестиции в автоматизацию процессов, документирование процедур и обучение команды окупаются многократно. Важно разделять окружения (dev/stage/prod), прогонять миграции данных на тестовых стендах и иметь отлаженные runbook’и для типовых инцидентов. Чётко организованные пайплайны и правила допуска в production заметно снижают количество инцидентов в рабочее время .
Похожие материалы
 Аренда микроавтобуса без водителя: что нужно знать и как не допустить ошибок
Аренда микроавтобуса без водителя: что нужно знать и как не допустить ошибок Хьюмидор: как сохранить сигары в идеальном состоянии и не испортить удовольствие
Хьюмидор: как сохранить сигары в идеальном состоянии и не испортить удовольствие Морская рыбалка в Дананге: форматы выходов, рыба, сезоны и цены
Морская рыбалка в Дананге: форматы выходов, рыба, сезоны и цены- Модельный ряд и характеристики Dongfeng
- Ключи остались в машине: что делать и как не усугубить ситуацию
- Обзор внедорожных режимов TANK: электроника, которая едет вместо вас